Intel 16nm
SoC Tapeout
Table of Contents
UC Berkeley EE194/290C SoC Tapeout Course Project
Spring 2025 | Advised by Professor Pister, Professor Chien, and Professor Jain
Note: Implementation details under Intel NDA
Overview
I worked on the tapeout of a 500 MHz multi-core RISC-V system-on-chip as part of UC Berkeley’s EE194/290C SoC Tapeout Course (Spring 2025, advised by Professors Pister, Chien, and Jain). It was enabled by Intel’s academic collaboration with UC Berkeley and fabricated with Intel 16nm process, targeting digital signal processing (DSP) and machine learning workloads. The chip was developed as part of a 15-week end-to-end SoC tapeout effort using an open-source hardware toolchain.
My role focused on architectural configuration, design-space exploration, and system-level performance evaluation, with an emphasis on DSP workloads using the Saturn vector core. Through benchmark-driven exploration of core and cache parameters under area, power, and frequency constraints, my team improved achievable frequency from ~400 MHz to the final 500 MHz target while maintaining performance scalability.
I also led the development of software workloads and microbenchmarks to stress-test the full system, including a vectorized audio fingerprinting application that exercised our custom accelerators as a proof-of-concept for hardware bring-up.
My overall role in this tapeout emphasized architectural decision-making and benchmarking under realistic SoC constraints, rather than RTL micro-optimization.
At a Glance
- Technology: Intel 16 nm SoC
- Frequency: 500 MHz target
- Architecture: Multi-core RISC-V with vector acceleration
- Focus Chip: DSP’25
- My Role: Architecture exploration, benchmarking, system-level performance evaluation
- Tapeout: Yes (academic SoC)
Note on Confidentiality
This project was conducted under a Non-Disclosure Agreement with Intel. Detailed RTL, place-and-route layouts, and certain implementation specifics (process parameters, etc.) cannot be publicly shared. Performance results shown reflect pre-silicon simulation and architectural exploration completed during the course.
Project Context
This project was completed as part of an intensive SoC tapeout course that took designs from initial architecture to manufacturing in 15 weeks. The design leveraged an open-source tool stack built around Chisel, Chipyard, TileLink, and Hammer, enabling rapid iteration across architecture, implementation, and evaluation.
Two chips were taped out during the course: BearlyML’25 and DSP’25.
My work focused primarily on DSP’25, which targets real-time audio and signal processing applications.
- Link to the course: UC Berkeley EE194/290C
- Link to Saturn documentation: Saturn Vector Core (saturn-vectors.org)
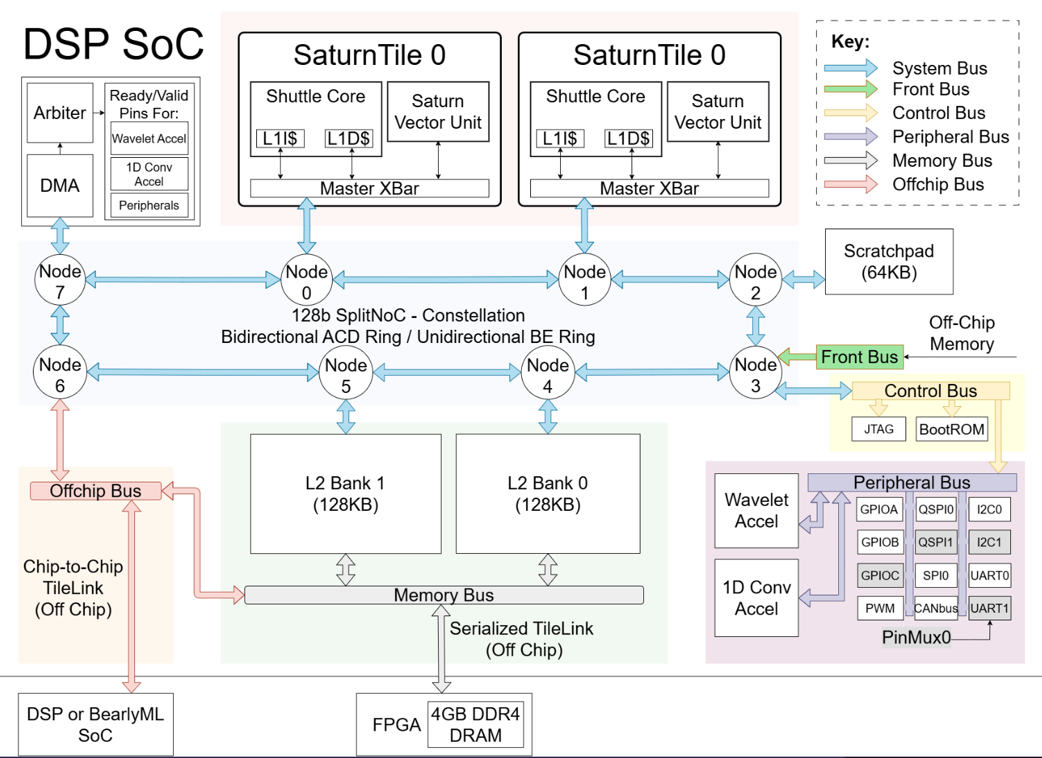
DSP’25 System Architecture
DSP’25 is designed for high-throughput audio processing and includes:
- Two Saturn tiles, each combining:
- A Shuttle Tile (in-order, superscalar RISC-V core)
- A vector processing unit
- 256 KB inclusive L2 cache
- 64 KB scratchpad memory
- Dedicated DSP accelerators:
- 1D convolution engine
- Wavelet transform engine
- DMA engine for accelerator offload
- Split NoC topology for improved scalability
Saturn Vector Core
The Saturn core is optimized for data-parallel workloads common in DSP and ML. It supports vectorized floating-point and integer execution and integrates directly with the memory hierarchy.
Key characteristics:
- Configurable vector length and data width
- Vector register file managed within the core
- Vector load/store units bypass the scalar L1 via a high-bandwidth vector port to coherent memory.
- Support for mixed scalar–vector execution
The DSP’25 Saturn core targeted a 2 ns clock period (500 MHz); timing closure was achieved within an ~80 ps clock uncertainty, meeting tapeout signoff criteria.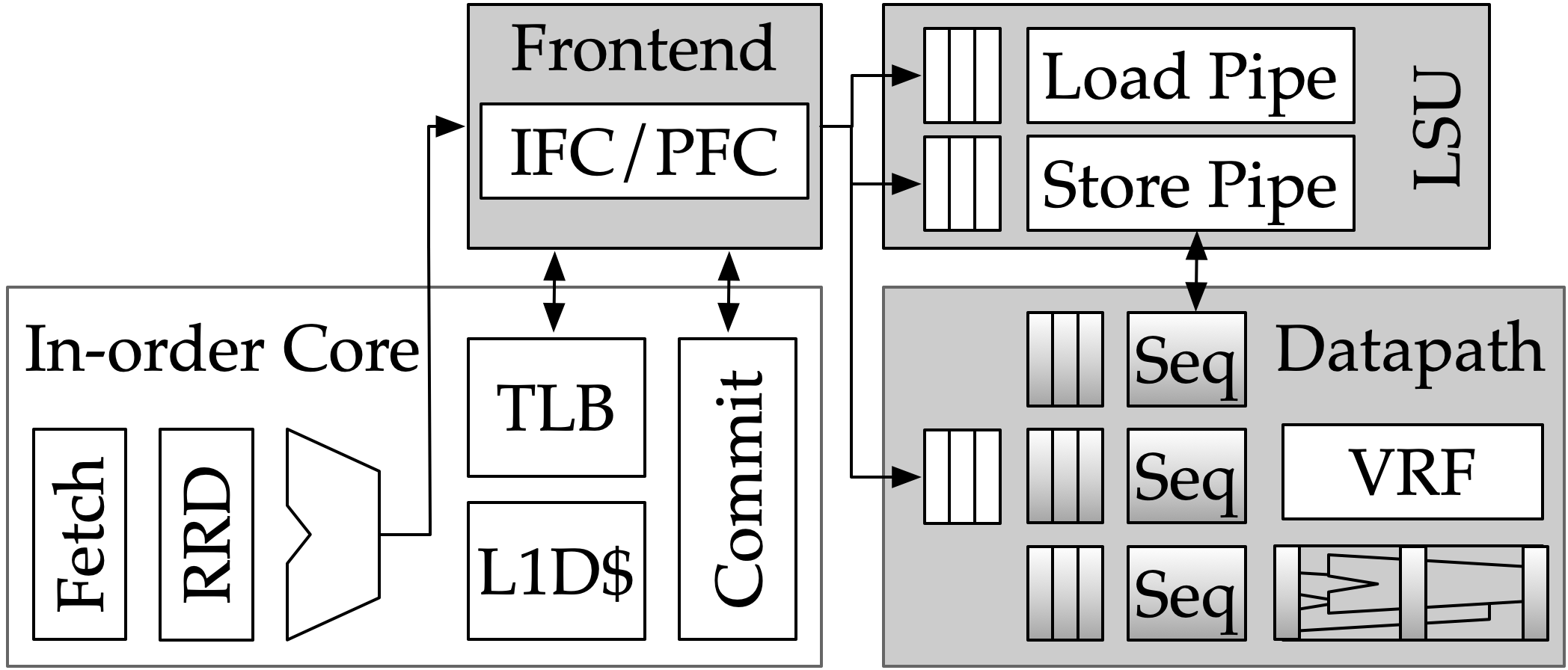
My Contributions
Note that all performance results shown here reflect post-synthesis, cycle-accurate simulation under signoff clock constraints. Silicon validation and integration were in scope for the tapeout and were performed by other members of my team; my contributions focused on pre-silicon architectural exploration, benchmarking, and system-level performance evaluation.
Area constraints and timing closure were shared team responsibilities and were evaluated post–place-and-route across the full SoC.
1) Architectural Design-Space Exploration
I led benchmark-driven exploration of Saturn core and cache configurations, evaluating tradeoffs across:
- Issue queue depth and structure (unified vs. split topologies)
- Vector length and data length parameters
- Cache sizing and hierarchy choices
- Accelerator integration strategies
Rather than optimizing individual blocks in isolation, I focused on system-level performance under realistic workloads, balancing throughput, area, and achievable frequency.
2) Saturn Microbenchmark Suite
To guide architectural decisions, I developed a comprehensive Saturn microbenchmark suite used for correctness and performance evaluation.
The suite included stress testing vector arithmetic, transcendental functions, matrix operations, convolutions, control-heavy kernels, and accelerator-focused tests. Benchmarks were written in both scalar and vectorized forms and run across many SoC configurations.
Full design-space sweeps were infeasible because of the efficiency cost of rebuilding and testing multiple chip variants to capture performance and PPA trends. Thus, we implemented a design → test → evaluate → repeat loop to focus exploration on configurations with the largest performance impact. I automated benchmark execution and data collection with multithreaded and multiprocess Python scripting to run at scale on our shared compute cluster to streamline RTL synthesis for configuration changes, data collection, and benchmark analysis.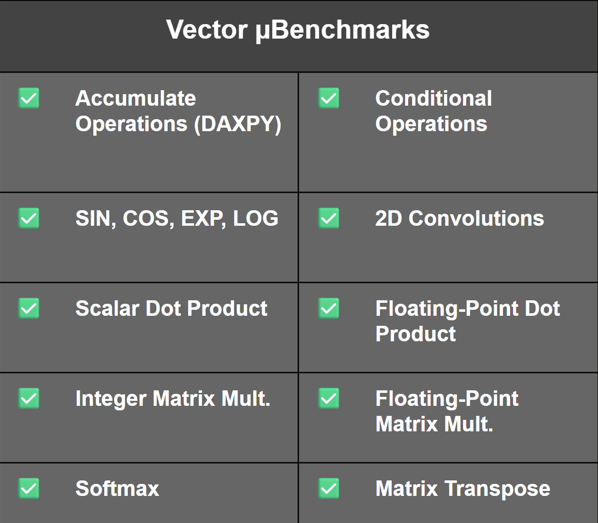
3) Base Saturn Core Performance Results
Although the previous Saturn core had been characterized in prior work, my team re-evaluated its performance under DSP’25 system constraints (area, power, frequency) and with updated workloads that modeled our target applications.
While absolute performance varied with configuration, the Saturn core consistently delivered tens-to-hundreds-fold speedups over pure scalar implementations over a range of workloads. Take the following representative examples:
64×64 outer-product matrix multiply (int8 → int32):
- Scalar: ~3.2M cycles
- Saturn: ~70k cycles
- ~46× speedup
3×3 convolution (int8 → int16, 32×512 input):
- Scalar: ~2.5M cycles
- Saturn: ~18k cycles
- ~135× speedup
These results were representative of the broader benchmark suite and directly informed architectural and configuration decisions.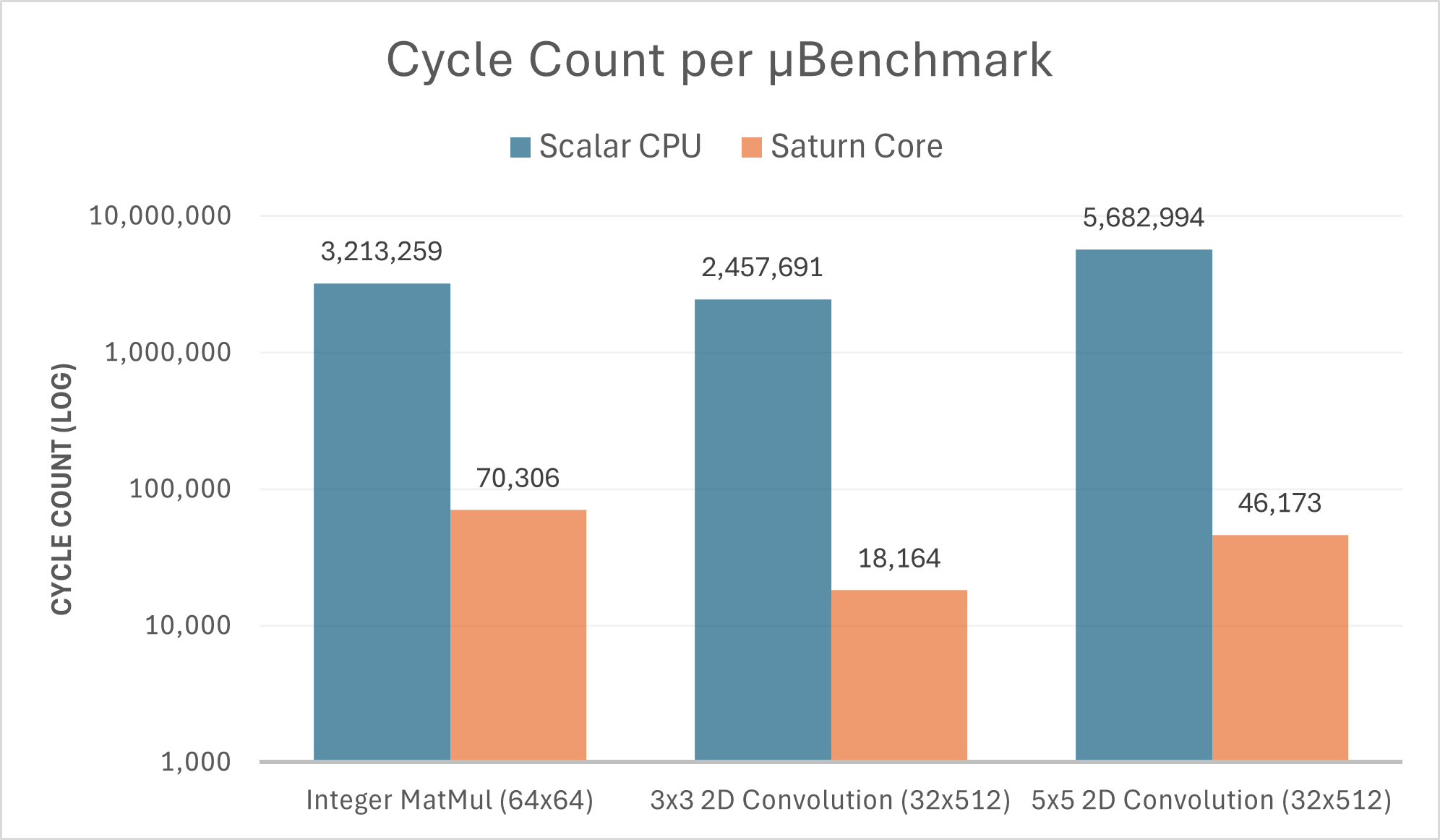
4) Software-Guided Hardware Decisions
Benchmark results were used to drive concrete design decisions.
For example, when exploring issue queue configurations:
- Increasing queue depth yielded modest (5–10%) performance gains
- Splitting issue queues significantly improved workloads that interleave vector floating-point and integer operations
- The performance gains justified the area increase for DSP’25 target workloads
This workflow ensured that architectural changes translated into measurable application-level improvements rather than isolated micro-optimizations, and directly informed the DSP’25 tapeout configuration and was reflected in the final physical implementation. Based on these results, we selected a split issue queue with depth = 8, as the performance gains outweighed the associated area increase.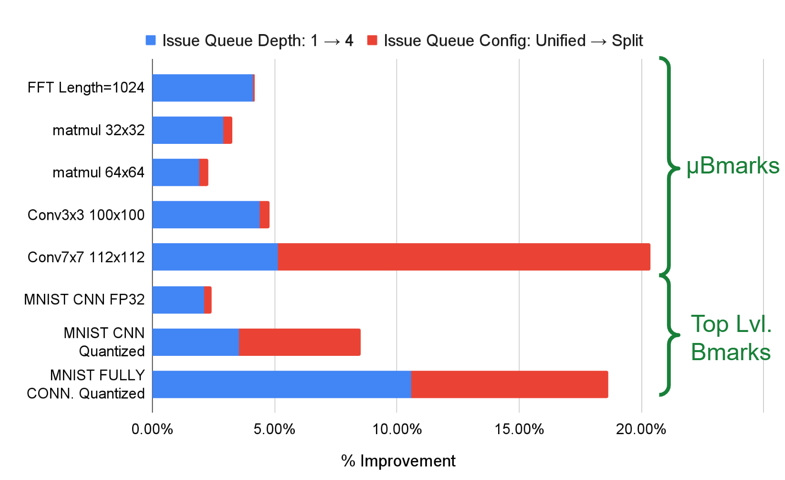
Additionally, in some cases, benchmark results showed that our carefully optimized vector kernels outperformed dedicated accelerators, reinforcing the importance of validating hardware assumptions against real workloads.Full Configuration List
Similar measurements were conducted for: - Vector length and data width
- Data width
- Issue queue configuration and sequencer topologies:
- Unified (single issue queue)
- Shared (shared FP/Integer queue)
- Split FP/Int (dual-issue queue)
- Multi-ALU (dual-issue integer ALU operations)
- Multi-MAC (dual-issue integer multiply-accumulate operations)
- Multi-FMA (dual-issue floating-point multiply-accumulate operations)
- L1 Cache sizing
- L2 Cache sizing
- NoC configurations:
- Single vs. split NoC
- Flit width
- Buffer sizing
- Tightly-Coupled Memory (TCM) inclusion and sizing
- Scratchpad memory sizing
- Saturn vs. Shuttle Core inclusion (superscalar execution)
5) Top-Level Application: Audio Fingerprinting
I led the design of DSP’25’s top-level application: a vectorized audio fingerprinting pipeline inspired by the structure of real-time audio matching systems like Shazam or Google Assistant’s “Hum to Search.”
I designed the application pipeline to leverage all of the SoC’s blocks, featuring both the Wavelet and 1D-Convolution DSP accelerators, the revised DMA engine, and the Saturn vector core to extract 64-bit audio fingerprints from input signals.
- Audio input: GPIO peripherals capture signal and store to memory via DMA (software-simulated in our environment).
- Wavelet Transform: MMIO Accelerator performs a spectral analysis and creates a frequency map.
- 1D Convolution Accelerator: on-core accelerator performs peak detection.
- Saturn Vector Core: executes a custom Locality Sensitive Hashing algorithm (SimHash) to generate compact audio fingerprints and detect feature matches against a database
The application demonstrated how Saturn vector capabilities and DSP accelerators could be composed to extract robust audio features. Due to simulation performance limits, this was validated as a working software model intended for hardware bring-up in later phases. Post-silicon validation and integration were carried out by other members of the team.
| Description | Audio (21800 Samples) | 64-bit Hash | Similarity Score (x/64) |
|---|---|---|---|
| “Hello” | 0xc79440065d452fce | 64 ✅ (Exact Match) | |
| “Hello” Distorted | 0xc79440065d452fce | 41 ✅ (High Correl.) | |
| “Apple” | 0xc79440065d452fce | 33 ❌ (No Similarity) |
Documentation and Bring-Up Support
To ensure that architectural optimizations were usable by the software team, I prioritized documentation and developer guidance. I authored detailed internal documentation and usage examples for vector programming on Saturn, using the microbenchmark suite as a reference implementation.
This reduced friction during bring-up and helped ensure that hardware capabilities translated into real performance gains.
Engineering Takeaways
- System-level constraints (cache hierarchy, NoC topology, timing closure) dominated achievable performance more than isolated core optimizations.
- Configuration and architectural parameters can materially affect frequency closure under fixed tool and schedule constraints.
- Software workloads are essential for validating hardware modules and quantifying assumptions from microarchitectural optimizations.
- Documentation and tooling are critical for effective hardware–software handoff.
Team and Acknowledgments
This project was completed as part of a collaborative team effort in UC Berkeley’s EE194/290C course (Spring 2025). I acknowledge my teammates’ contributions to physical design, RTL implementation, and system integration during the tapeout phase. Special thanks to Professors Pister, Chien, and Jain for their guidance throughout the project.
I graduated shortly after the May 2025 tapeout. Post-silicon bring-up and validation were performed by the Fall 2025 course cohort. My contributions and this project writeup focus on the pre-silicon phases: architectural design-space exploration, benchmarking, and application development. I provided documentation and test infrastructure to support the subsequent bring-up effort, and the DSP’25 chip was successfully validated for audio analysis applications.